どんなもの?
- SQLite の歴史的展望を示す。アーキテクチャの簡潔な説明も提示する。
- DuckDB をベースラインとして使用して特徴的なワークロードに対する SQLite の徹底的な評価を提供する
- 分析データ処理用に SQLite を最適化する。SQLite の主なボトルネックを特定し、考えられる下記欠作の長所と短所について説明する。最適化を適用した結果、SSB(DWH 向けのベンチマークツール) 全体で4.2 倍のスピードアップが実現した
- ライブラリフットプリントや BLOB 処理パフォーマンスなど、埋込み型データベースエンジンに固有のパフォーマンス測定値をいくつか特定する
- SQLite のパフォーマンスをさらに改善するための潜在的な将来の方向性の概要を説明する
先行研究と比べてどこがすごい?
SQLite のパフォーマンス動作の根本原因を特定しようとする研究は行われていない
論文より
技術や手法のキモはどこ?
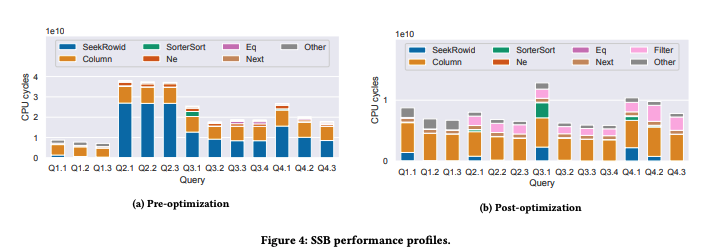
SQLite の実行エンジンのプロファイルを作成し、ボトルネックを発見した。VDBE Profile を ON にしてSQLite をコンパイルすることでVDBEが実行に費やすCPUサイクル数が見れるようになる。
 原文より引用
原文より引用
結果、SeekRowId が多くのCPU時間を専有していた。今回で言う SeekRowid 命令は、ファクト・テーブルとディメンジョン・テーブルの間でインデックス(B-Tree)結合を実行する。どうも3つ以上のテーブル使おうとするとそれが行われる様子。
そのため、不要なインデックス結合(インデックス探索)を避けられないか検討した。
なぜかというと、SQLite のjoin が貧弱なため。
SELECT Sum(lo_revenue),
d_year,
p_brand1
FROM lineorder,
date,
part,
supplier
WHERE lo_orderdate = d_datekey
AND lo_partkey = p_partkey
AND lo_suppkey = s_suppkey
AND p_category = 'MFGR#12'
AND s_region = 'AMERICA'
GROUP BY d_year,
p_brand1
ORDER BY d_year,
p_brand1;
具体的には、ブルームフィルターを使用して、Lookahead Information Passing を実装した。
これは、等結合クエリの実行を高速化するために Quickstep システムで仕様される主要な手法。同様の手法は他の商用システムでも使用されている。
論文を読んだ感じ、ハッシュテーブル検索前にブルームフィルタを適用して、結合コストを下げていそう。
どうやって有効だと検証した?
検証前と同一条件でベンチマークを実行した
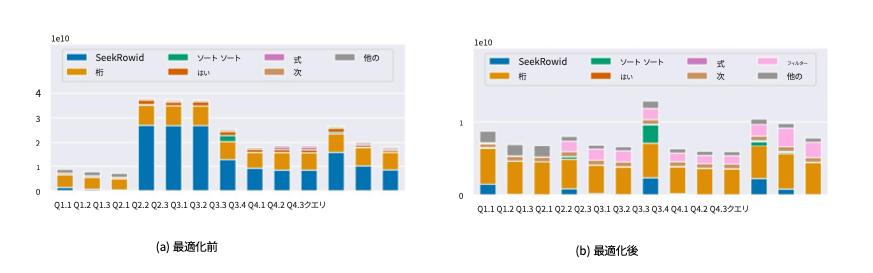 原文より引用
原文より引用
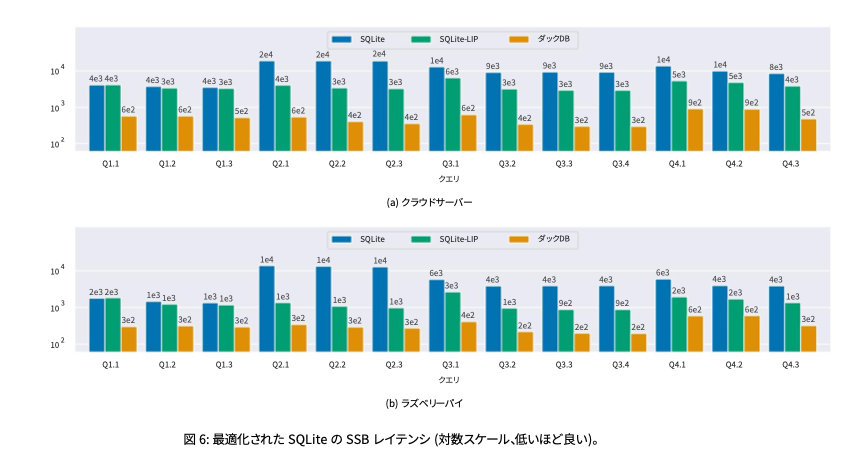 原文より引用
原文より引用
議論はある?
値抽出(テーブル内の特定の行と列の値を取得する基本的な操作)の最適化はデータベースファイル形式の変更に関する制限にあたったためできなかった。ファイルを変更したくないのは、SQLite のメリットであるポータビリティや安全性を破壊する可能性があるため。SQLite3/HE ではそのあたりをうまく解決している模様。
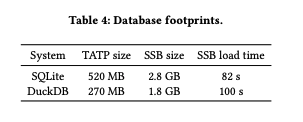
SQLiteはCSV(TATPデータセット100万件)からSSBデータセットを読み込む際にDuckDBより20%近くも高速になります。しかし、CSVデータをどちらのシステムにも読み込むのに必要な時間には驚かされました。DuckDBはSSBをすべて実行するのに約7秒しかかかりませんが、データのロードには100秒かかります。SQLiteは、SSBの実行に51秒かかりましたが、データの読み込みには82秒かかりました。データサイエンス分野でCSV形式が広く使われていることを考えると、この結果はCSVの読み込みをどのように高速化できるかをさらに検討する動機付けになります。
次に読むべき論文は?
-
SQLite3/HE
- SQLite3/HE は、SQLite3 に最新の分析クエリ処理機能を追加し、100倍から1000倍の高速化を実現しました。 SQLite3/HEは、トランザクションクエリの性能を犠牲にすることなく、既存のSQLite3/HEを置き換えることができます。
- youtube
- Martin Prammer, Suryadev Sahadevan Rajesh, Junda Chen, and Jignesh M. Patel.
- Introducing a Query Acceleration Path for Analytics in SQLite3. In 12th Annual Conference on Innovative Data Systems Research (CIDR ’22).
- Lookahead Information Passing (LIP)
-
LIP概略
ここで、LIP戦略の概要を説明する。
- 構築段階。結合木の各次元テーブルについて、ハッシュテーブルと、ブルームフィルタのような簡潔なフィルタデータ構造の両方を、選択結果に対して構築します。このフェーズについては、セクション3.1.1で詳しく説明します。
- ブルームフィルタの探索段階。次に、ファクトテーブルを用いて、ヒット/ミスの統計をとりながら、これらすべてのフィルタを同時にプローブする。
- 適応的な並べ替え段階。推定された選択性を用いて、探索中のフィルタを適応的に並べ替える。フィルタ構成を適切に選択すれば、この多方向フィルタ探索の結果は、最終的な出力結果とほぼ一致する(ただし、いくつかの誤検出がある)。このアルゴリズムについてはセクション3.2でより詳細に述べる。
- ハッシュテーブルプローブ段階。続いて、ハッシュテーブルを調査し、偽陽性を排除するとともに、さらなる処理に必要なビルドサイド属性を収集する。このように、簡潔なフィルタデータ構造(ブルームフィルタなど)を用いることで、このようなマルチジョインクエリにおけるハッシュテーブル探索コスト(主要なコスト項)を大幅に削減することができるのです。
実際、セクション4.2.2で示すように、ハッシュテーブルプローブはナイーブ評価による最適プランよりさらに少なくなります。しかし、LIPフィルタ自体の構築とプロービングのコストが追加されます。LIPデータ構造(本論文ではブルームフィルタ)はハッシュテーブルよりも空間効率が良く、プロセッサのキャッシュに収まる可能性が高いため、プローブコストを最小限に抑えることができ、バランスとしてはやはり高速化されます。また、このようなフィルタのサイズが小さいため、観測された選択性に基づいて、そのプローブを動的に並べ替えることができます。この適応的な並べ替えにより、オプティマイザが選んだ結合順序にかかわらず、フィルターへのプローブ数が最適な結合順序で必要なハッシュテーブルのプローブ数に近くなるようにします。実際、ほぼすべての結合順はほぼ同じ実行時間を示し、その時間は最適実行時間とほぼ等しい(またはそれ以上)。
用語
OLAP → Online Analytical Processing の略であり、データベース(DB)上に蓄積された大量のデータに対して集計や複雑で分析的な問い合わせを行うこと
OLTP → Online Transaction Processing 多数のトランザクションを同時に実行するデータ処理 ****
上記はOracle のページがわかりやすかった
DuckDB → 分析ユースケースに向いた SQLite のようなデータベースエンジン
特定ファイルをDuckDBに読み込ませてデータ分析ができるようになる。
そのため、大量トランザクションを扱うようなユースケースには向いてない。
列志向、マルチスレッドで動く
TATP ベンチマーク → 典型的な通信アプリケーションにおけるデータベースシステムの性能を測定するために設計されています。このベンチマークは一定の確率でランダムに生成される7種類のトランザクションから構成され80%は読み取り専用で、20%は更新、挿入、削除を伴うものである。関連する研究で広く利用されている。
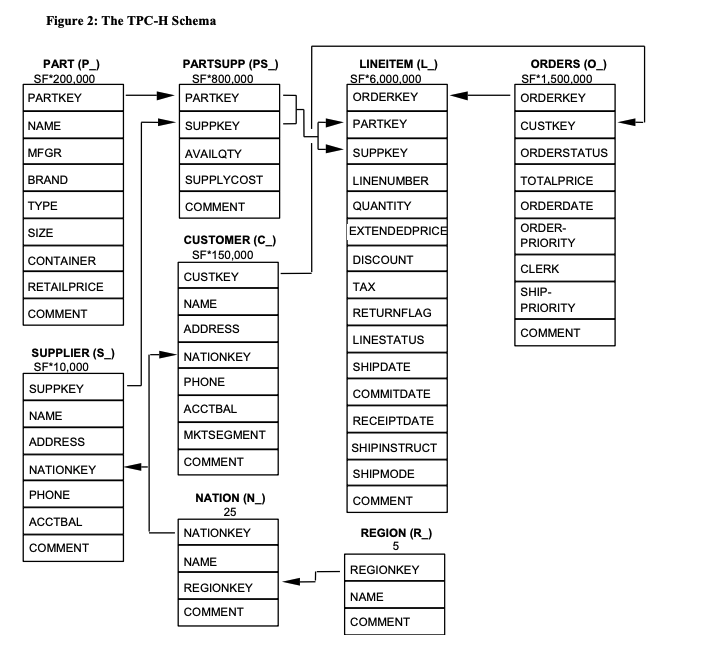
TPC-H schema → DWH 向けのベンチマークデータセット
Transaction Processing Performance Councilの略であり、トランザクション処理性能評議会である
↓
TPC-XX についての解説
SSB → Star Schema Benchmark OLAP ベンチマークに使うデータセットとそのクエリ 今回の論文で用いられている。(元データリンク)
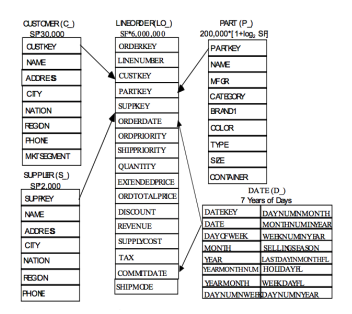
Q1.1
SELECT Sum(v_revenue) AS revenue
FROM p_lineorder
LEFT JOIN dates
ON lo_orderdate = d_datekey
WHERE d_year = 1993
AND lo_discount BETWEEN 1 AND 3
AND lo_quantity < 25;
Q2.1
SELECT Sum(lo_revenue) AS lo_revenue,
d_year,
p_brand
FROM p_lineorder
LEFT JOIN dates
ON lo_orderdate = d_datekey
LEFT JOIN part
ON lo_partkey = p_partkey
LEFT JOIN supplier
ON lo_suppkey = s_suppkey
WHERE p_category = 'MFGR#12'
AND s_region = 'AMERICA'
GROUP BY d_year,
p_brand
ORDER BY d_year,
p_brand;
-
Bloom Filter → この資料みれば○
-
Database 利用でのわかりやすい例(記事)
- スキャンしたデータから Bloom Filter を構築。スキャン量は変わらないのでメモリ使用量は変わらない。Bloom Filter を利用することによりマッチする確率の高いもののみ(偽陽性含むため)次の結合処理に回せるので効率的。結合元が100万、結合対象が1000のときには結合対象のデータ数くらいにフィルタしてから結合していける。探索するO(n)の絶対数が減らせるのが強みなのかなと。HashMapつくればアクセス早くなりそうだけど、多のデータの結合で重複データのときはkeyが上書きされるからやらないのかな。そこもkeyに対して配列持てば解決しそうな気がするけどどうなんだろう。
-
-
QuickStep
- Quickstepは、高性能なデータベースエンジンです。1)データをベアメタルの速度でインサイトに変換し、(2)SQLを含む複数のクエリーサーフェスをサポートし(最初と現在のバージョンはSQLのみをサポート)、(3)あらゆるハードウェア(ラップトップでの実行、ハイエンド(シングルノード)サーバーでの実行、分散クラスターでの実行を含む)でベアメタルの性能を実現するように設計されています。プロジェクト開始当初から、まず高性能なシングルノードシステムを提供し、その後、分散システムを提供する計画でした。apache 財団の project。
- 2018 年に活動停止している
- 論文
SQLite について
-
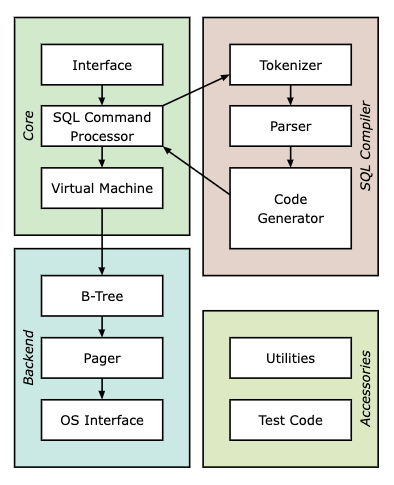
-
シングルスレッド
- オプションでマルチスレッドの外部マージソートアルゴリズムを使用する
-
VDBE
- データベースエンジン。生成されたバイトコードプログラムのロジックを実行する責務をもつ。SQLite の心臓!
-
ROWID
- テーブルに用意されている非表示のカラム。テーブルにデータを追加するごとに自動的に ROWID にも値が設定される。
-
-
ループ結合のみ、ネストとして扱う
- From 区の左端のテーブルが外側のループを形成。それ以降が内側のループを形成する。
-
-
- バージョン 3.39.0 (2022-06-25)の時点で、SQLite ライブラリは約 151.3 KSLOC の C コードで構成されています。(KSLOC とは、数千の「コードのソース行」、つまり空白行とコメントを除いたコード行を意味します。)比較すると、プロジェクトには 608 倍のテスト コードとテスト スクリプト (92038.3 KSLOC) があります。